
This post follows a question that I asked on stackoverflow several months ago. I did not receive a satisfactory answer at that time. I will expose the solution that we found at Keluro for this problem.
At Keluro, our client app products (for example the VSTO KMailAssistant, KBilling and the SPA web apps) communicate with a REST web api. This web api uses EntityFramework 6.0 on top of SQL Server for the persistence. However, some of our web api deployments are not necessarily multitenant. Indeed, we do have multiple clients who do not want to share their infrastructure, they demand an isolated deployment mainly for security and confidentiality reasons. For us, in order to keep things simple, it was important to be sure that all of our client deployments share the same database schema, even if they got into production at a different step during the development of the products. Consequently, we have N deployments of our web api with as many database catalogs. We also want to have all our web api deployments to be up-to-date compared to a stable revision of the source code. To this aim, a continuous build is in charge to update all these web api. Necessarily, the associated databases also need to be updated automatically. The Entity Framework is able, when the web app starts, to handle the migration process (if needed), the topic of this post is to propose a rigorous methodology to manage the migrations.
Entity Framework Code First supports migrations (see documentation here). To answer the problem explained above, when reading the documentation it is not clear how we should use the migrations. Indeed, we are told to call Update-Database from Visual Studio or to use Enable-Automatic migrations. Let us explain how to use the set of features proposed by Entity Framework to handle multiple deployment in a clean and rigorous way. Note also that this approach works well for local databases that are deployed with your ‘rich client’ application, for example with SQL Server CE which we use for our VSTO addins KMailAssistant and KBilling.
TLDR; Determine a “stable production schema”: which is the database schema corresponding to the web app code for a stable branch/tag in your source control. Avoid the so-called AutomaticMigration and always create new code based migration using Add-Migration with respect to an empty database that have been updated to the “stable production schema” after applying all existing migrations. Do not use Update-Database command to update your database in production, let the framework do it for you at startup using the MigrateDatabaseToLatestVersion initializer. Then, when you release a new environment starts the application with an empty database. You will also have to take care of version control when working with feature branches.
Generating clean code based migrations
For the following, I will assume that you have read the Entity Framework documentation. It is very important that you decide what is the “stable database schema”. It corresponds to the schema determined by the source code (remind that we use EF Code First) for the selected revision in your stable branch or tag. We advise you to avoid the AutomaticMigrations. Actually, AutomaticMigration does not mean that the migrations created will be applied automatically (we will discuss how to do that latter). It means that the migration needed, which is the piece of SQL needed to change the database between its actual stated and what it should be, will be generated and applied on the fly. This is dangerous in our situation, think of our multiple deployments, they have not been started at the same time. Indeed, with automatic migrations some migrations could have been generated and applied for some older client environments while you have to push a new environment right now. Consequently, the history of automatically generated migrations could be different even for the same revision of the source code.
The best solution to avoid this situation is that all deployment share the same series of code based migrations. On a stable source code revision, the succession of existing code migrations applied to an empty database produce a database with the so-called “stable database schema” introduced above. Then, if a new client is deployed, an empty database (no tables, no data) is created and then all existing migrations will be applied automatically by Entity Framework when the web app starts the first time. For example, suppose that we have the following list of migrations: 201401050000000_MigrationA (January 5st 2014), 20150300000000_1MigrationB, 201504120000000_MigrationC, 201511150000000_MigrationD. This means that, if a client web app and its database is put in production on March 2015, all migrations will be applied (including MigrationA and MigrationB).
When using code base migrations, it is important to keep in mind that the migrations are presented as csharp files that represent the SQL instructions to be applied (e.g. drop a table, adding a column etc.). In addition, a given database has also a table _MigrationHistory which keeps all migrations that have been applied to it. Then, if all your web apps are up-to-date with respect to the same web app source code, for all your databases, you will get exactly the same rows in the table _MigrationHistory.
When an application starts, to automatically migrate the associated database to the latest migration, you have to run this code at startup (e.g. Globalasax.cs for an asp.net web app).
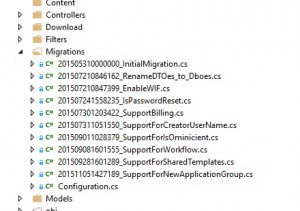
Keep a clean list of code based migrations
Let us explain how to keep a clean list of code migrations. I suggest to create a clean code based migration anytime a database schema change is required. To do so, you will need to use the Add-Migration command in your Package Manager Console in Visual Studio. Remind that if you do not specify a database connection string in the Powershell command, the connection string used will be the first found in your app.config or web.config file. This selected database may not have the proper “production schema”, it is error prone. My advice is to create only for the generation of this new code migration a database with no data but with the actual “production schema”. This is extremely simple and is also a sanity check of your existing migrations: create a new empty database, in one click in VisualStudio SQL Server Express (see picture below).
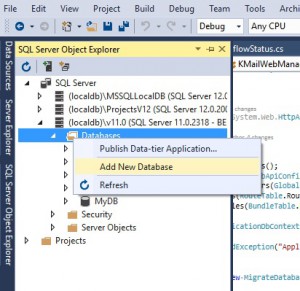
To update this database schema, take the connection string (right click on your database > Properties) then update the database by targeting the last migration, e.g.201511150000000_MigrationD, with the following command:
Then now this local database is “up-to-date” and you can generate your new migration named MigrationE (choose something more meaningful in your case) with the command:
Then the migration files are generated, it is recommended to read them and make sure they correspond to the changes you intended to introduce. Now they are ready to be committed in a single and clean commit. As we have seen the migration is prefixed with number which corresponds to its generation date (e.g. 20150501000000_MigrationE). This number is effectively used by when using the MigrateDatabaseToLatestVersion database initialize and it can be a problem when not carefully used with version control.
Migrations and version control
There may be troubles when branching, to see this let us explain how the Entity Framework applies the code base migrations. Have a look at the table _MigrationHistory, the rows are the migrations, the date when the migration was generated is also there, because it is included in the name of the migration. Entity framework takes the date of most recent migration applied in the _MigrationHistory table and applies all migrations in the web app code that have been generated latter.
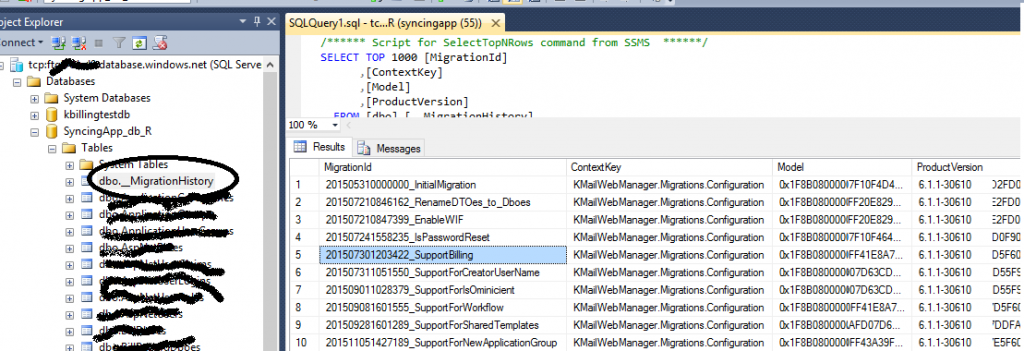
You see the potential problem? Say that you have created two feature branches: X and Y. Suppose that you have generated a migration for each of these branches, for X then for Y. But for some reason, you merged Y into your stable branch before X, the migration of X will not be applied!
To avoid this as much as possible, I suggest that you generate a minimum of migrations and , for each newly generated migration, put it in a dedicated commit with nothing but the code of the migration and with a clean indicator in the commit log (e.g. put a “[MIGRATION]” tag). Remark that the git rebase interactive command of git can be useful (take care when rebasing pushed commits!). For example you can remove all intermediate [MIGRATION] commits and regenerate a single one. or if you decide that a migration (not deployed!) is no longer needed you can drop the commit etc. I think it is wise thing to name a “database” master in your dev team. This person should be the one responsible for merging branches involving database migrations. He will be aware of the potential problem with migrations date generation and will know how to fix it.
Comments